


DGX Spark: aviso a navengantes
¿Vale la pena la DGX Spark? Te lo explico desde mi experiencia.

Tal y como va el mercado de los LLMs comerciales y cómo avanzan los modelos de pesos abiertos, me planteé hace unos meses comprar una NVIDIA DGX Spark para tener un equipo de escritorio potente para correr modelos de IA localmente.
Tras dar el paso (en mi caso fue ASUS Ascent GX10) y probar el equipo, me he encontrado con varios problemas que no se mencionan en los materiales de marketing. En esta guía, intentaré explicar de forma accesible qué es la DGX Spark, cuáles son sus limitaciones y qué se puede esperar de ella.
Características técnicas de la DGX Spark
| Componente | Especificación |
|---|---|
| Chip | NVIDIA GB10 Grace Blackwell Superchip |
| CPU | ARM 20 núcleos (10× Cortex X925 + 10× Cortex A725) |
| GPU | Blackwell — 6.144 CUDA Cores |
| RT Cores | 4.ª generación |
| Tensor Cores | 5.ª generación |
| Memoria | 128 GB LPDDR5X unificada (CPU + GPU coherente) |
| Ancho de banda | 273 GB/s |
| Almacenamiento | Hasta 4 TB NVMe |
| Rendimiento IA | 1 petaFLOP (FP4) |
| FP16 | ~100 TFLOPS |
| Conectividad | USB 4, USB-C, Ethernet 10GbE, Wi-Fi 7, Bluetooth 5.4 |
| Sistema operativo | DGX OS (Ubuntu 24.04 LTS) |
| Dimensiones | 150 × 150 × 50,5 mm (1,1 litros) |
| Apilable (Stackable) | 2 directos. Hasta 4 con switch |
El inicio del problema: Dos familias dentro de la misma generación
NVIDIA lanzó la arquitectura Blackwell en dos variantes con objetivos distintos:
- SM100: diseñada para centros de datos. Máximo rendimiento, sin límite de consumo eléctrico.
- SM121: diseñada para escritorio y dispositivos de bajo consumo. Es la que lleva el DGX Spark.
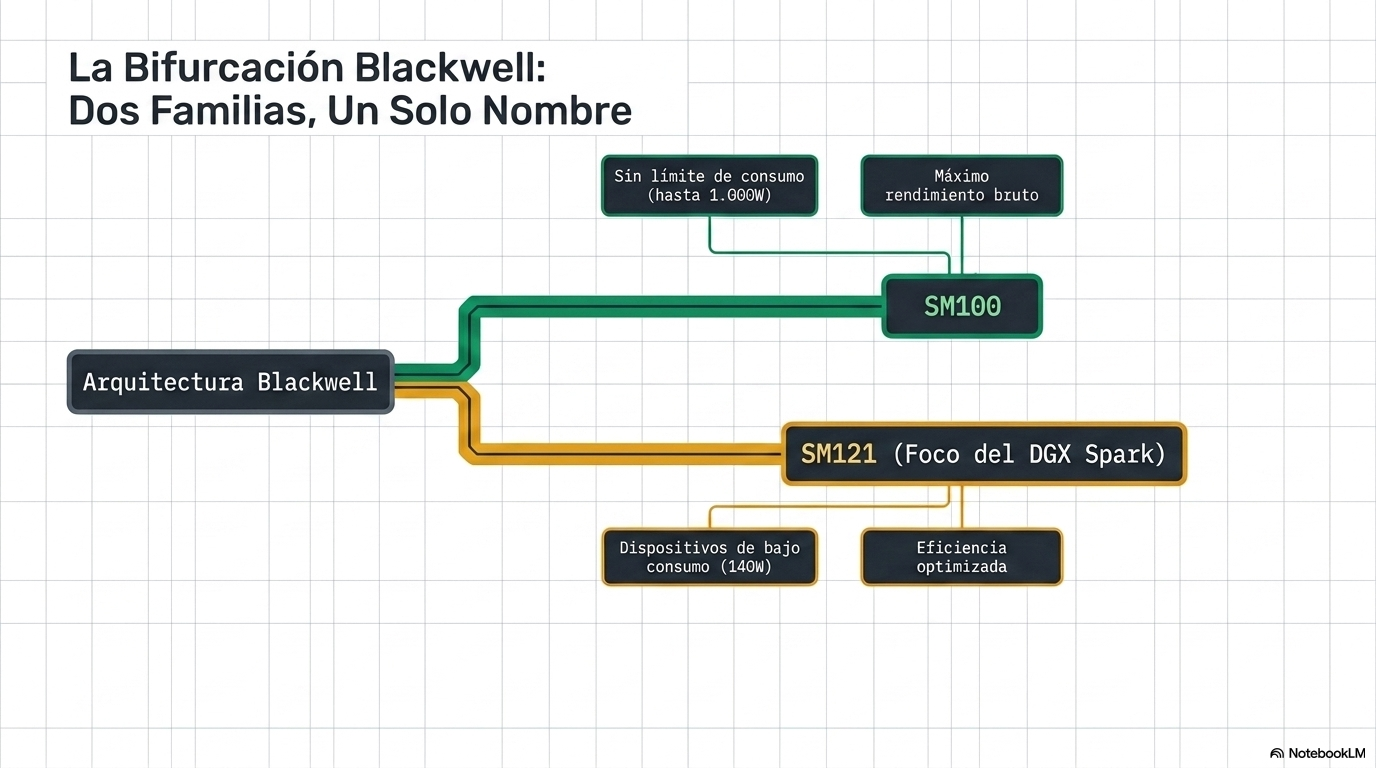
Aunque comparten nombre de generación, tienen diferencias de hardware significativas que afectan directamente a qué software puede correr en cada una.
Filosofía de las DGX Spark. Mercado de escritorio
En si, las DGX Spark están orientadas a tener una experiencia de usuario con un consumo de energía muy reducido, intentando hacerlo a un precio “asequible”.
Por el camino han tomado decisiones de hardware muy relevantes que ha creado un problema importante en el soporte del software para hacer correr modelos locales. La arquitectura que hay en los SM121 difieren mucho de sus homólogos de Datacenter, y eso hace que ciertas piezas de hardware no sean útiles en los modelos SM121, con lo que no se han incuído, como los Tensor memory (TMEM).
El resultado práctico… los Tensor Cores del SM121 trabajan de forma más parecida a como lo hacían las GPUs de hace dos generaciones (Ampere).
El problema del software: Instrucciones incompatibles para DGX Spark
Esta diferencia de hardware provoca nos lleva a incompatibilidades de software. Los programas usan instrucciones específicas de cada arquitectura, y en este caso se ha convertido en un verdadero problema.
Las instrucciones más modernas (wgmma, tcgen05) están diseñadas para aprovechar las características del SM100. El SM121 no las soporta por sus diferencias de hardware. Cuando un programa intenta usar esas instrucciones en un DGX Spark, el compilador devuelve un error o el rendimiento cae drásticamente.
La tierra prometida del NVFP4 vs la realidad… y la comunidad al rescate (como siempre)
Ante la falta de soporte oficial en las herramientas habituales, la comunidad de desarrolladores ha creado soluciones a medida.
Estas optimizaciones funcionan, pero requieren trabajo especializado y no están integradas aún en las herramientas que usa la mayoría.
Lo más irónico (y doloroso al mismo tiempo) es que el DGX Spark es físicamente capaz de ejecutar cálculos en un formato de precisión muy reducida llamado NVFP4, propietario de NVIDIA, que en teoría permite alcanzar el máximo rendimiento del hardware con una alta precisión parecida a 8 o 16 bits. Pero no es posible usarlos por el problema soporte del software.
Como alternativa, a base de prueba y error… y mucha pericia, desarrolladores como Eugr y su repositorio han conseguido cristalizar todos los trucos aprendidos en los foros para poder correr modelos con una velocidad aceptable en otras quantizaciones como FP8 o INT4/Autoround, ya que el soporte de software para NVFP4 en el SM121 es actualmente muy inmaduro.
Aunque no es lo ideal, es una solución que permite usar el DGX Spark con modelos de IA locales, aunque con un rendimiento inferior al potencial máximo del hardware. Pero a unas velocidades bastante decentes, y con una precisión suficiente para muchos casos de uso.
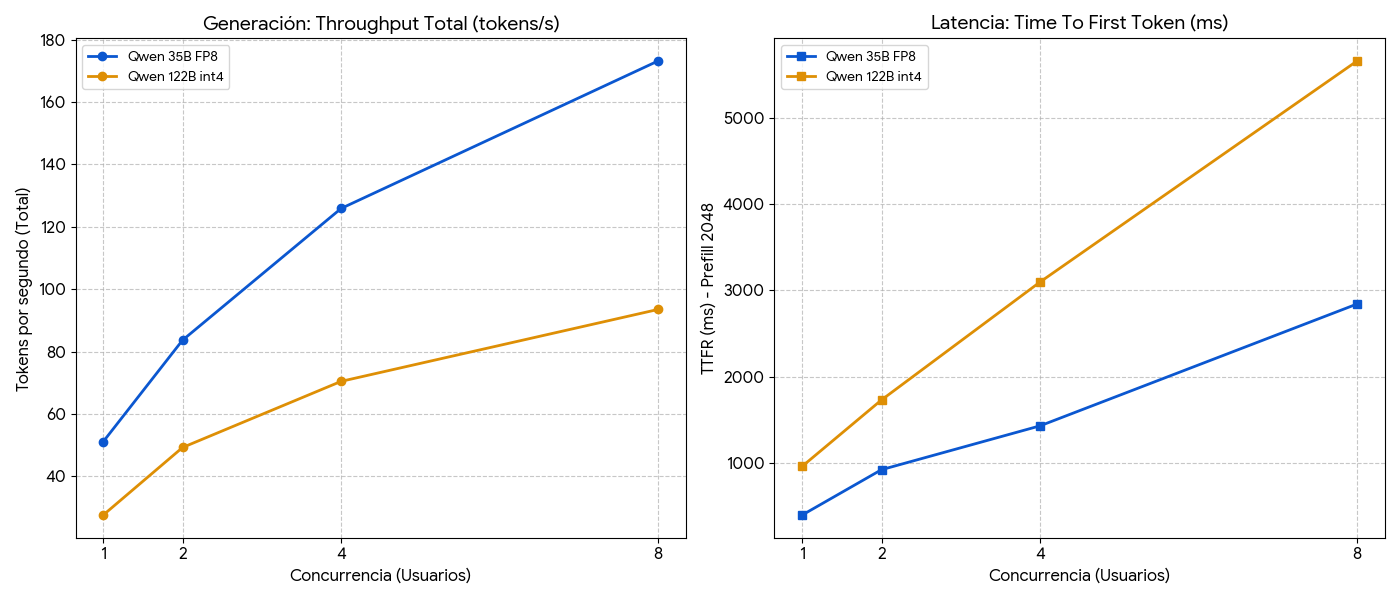
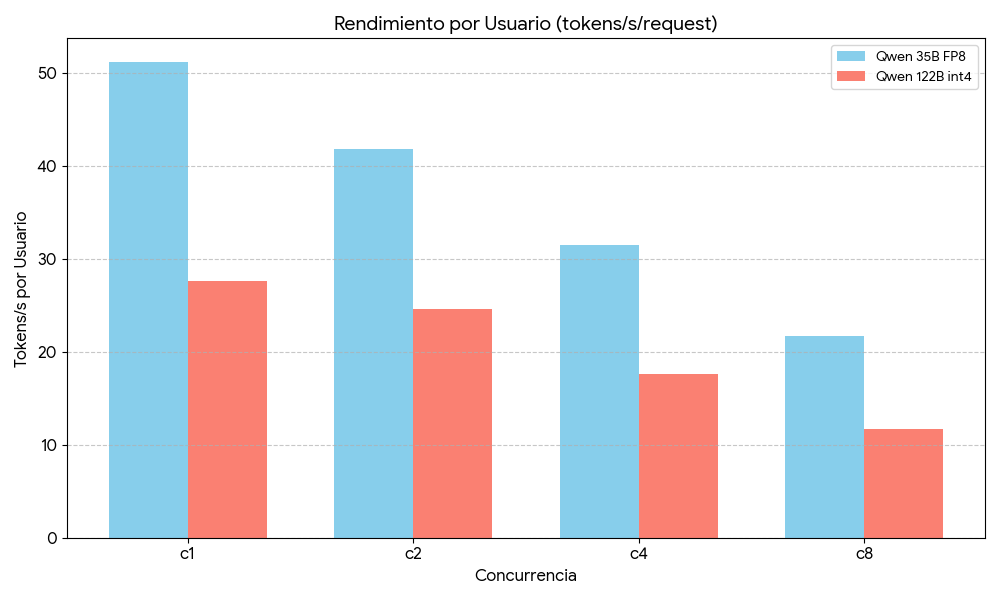
A la espera de llegar a usar NVFP4 nativo…

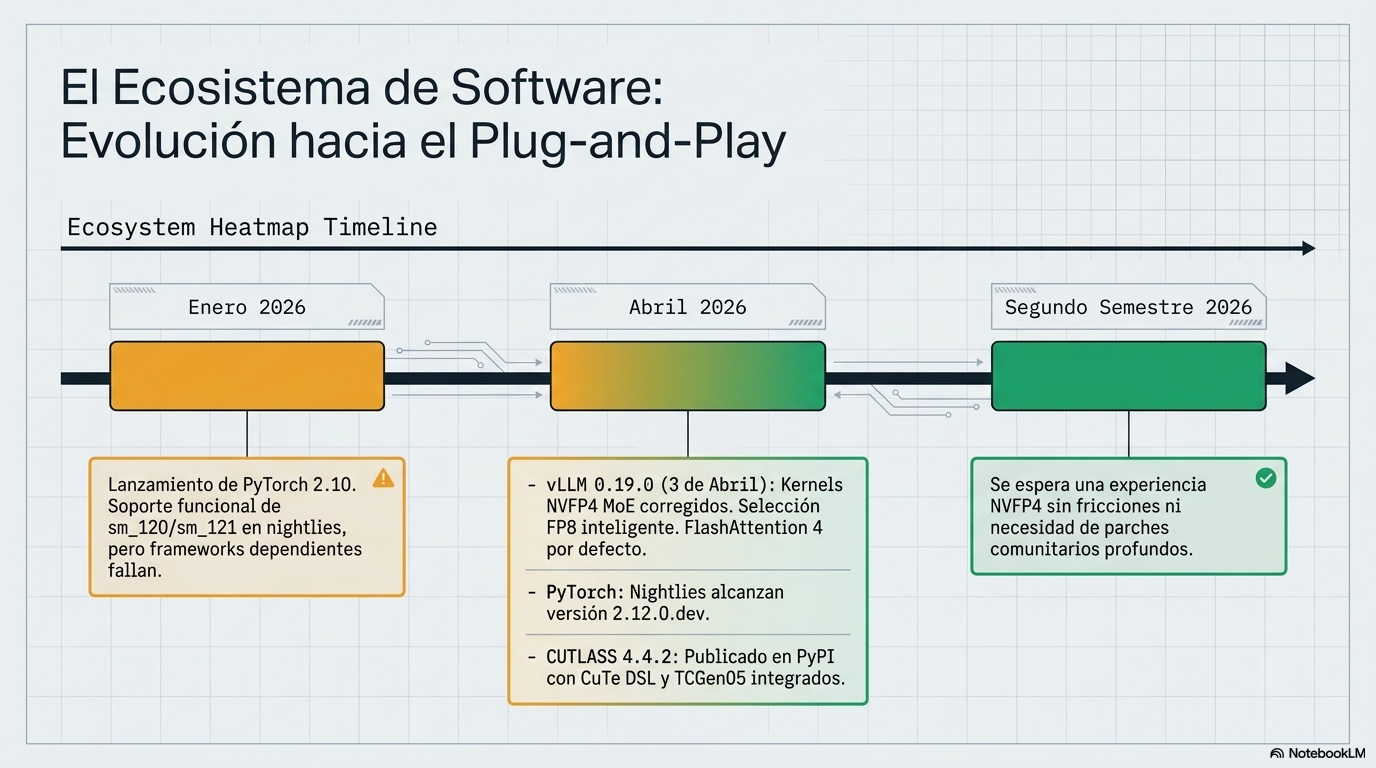
Hoja de ruta según redes para llegar al rendimiento real
Siguiendo foros, redes y posibles bulos… esta sería una hoja de ruta para alcanzar el rendimiento real del DGX Spark.
La guinda de todo esto. El problema de alimentación y el modo degradado de las DGX Spark
No os lo vais a creer, pero hay un fallo normalmente al apagar las Spark que hace que al volver a arrancar, trabajen en modo degradado. Si sucede, la solución es… ojo al dato… desconectar el cargador del ordenador, esperar unos minutos a que se descarguen los condensadores…y volver a conectarlo. No sirve apagando o reiniciando.
Conclusión
Salvando los baches que están apareciendo por el camino… tal como evolucionan los modelos de pesos abiertos como Qwen o Gemma, y como se está poniendo el mercado de IA de pago por uso comercial… opino que la DGX Spark es un producto real y útil, pero con un perfil concreto.
Con las expectativas correctas y algo de trabajo adicional de configuración, puede ser una herramienta valiosa para IA local.
Eso sí… el inicio ha sido un poco accidentado (y sigue siéndolo), y el soporte de software es un tema a seguir de cerca en los próximos meses.
Referencias
https://github.com/Avarok-Cybersecurity/dgx-vllm
https://github.com/PrimitiveContext/blackwell
https://www.backend.ai/blog/2026-02-is-dgx-spark-actually-a-blackwell
Twitter
Facebook
Reddit
LinkedIn
Email